
1. 需求背景
团队Code Review规范缺少执行:大部分团队的 Code Review 停留在文档纸面上,成员之间口口相传,并没有一个工具根据规范来严格执行
信息安全问题:公司内代码直接调DeepSeek/ChatGPT/Claude会有安全问题,为了使用这些AI大模型需要对代码脱敏,只提供抽象逻辑,这往往更花时间
低质量代码耗费时间:代码审核人每天至少 10~20 个 MR 需要审核,大部分团队在提交MR时是没有经过单测的,仅仅是IDE的代码规范插件过滤了一些低级错误,但还有些问题(代码合理性、经验、相关业务逻辑等)需要花费大量时间。所以可以先经过自动化审核,再进行人工审核,可大大提升CR效率
开源大模型 + 本地知识库 = 代码审核助手(CR-Copilot)



2. 实现思路
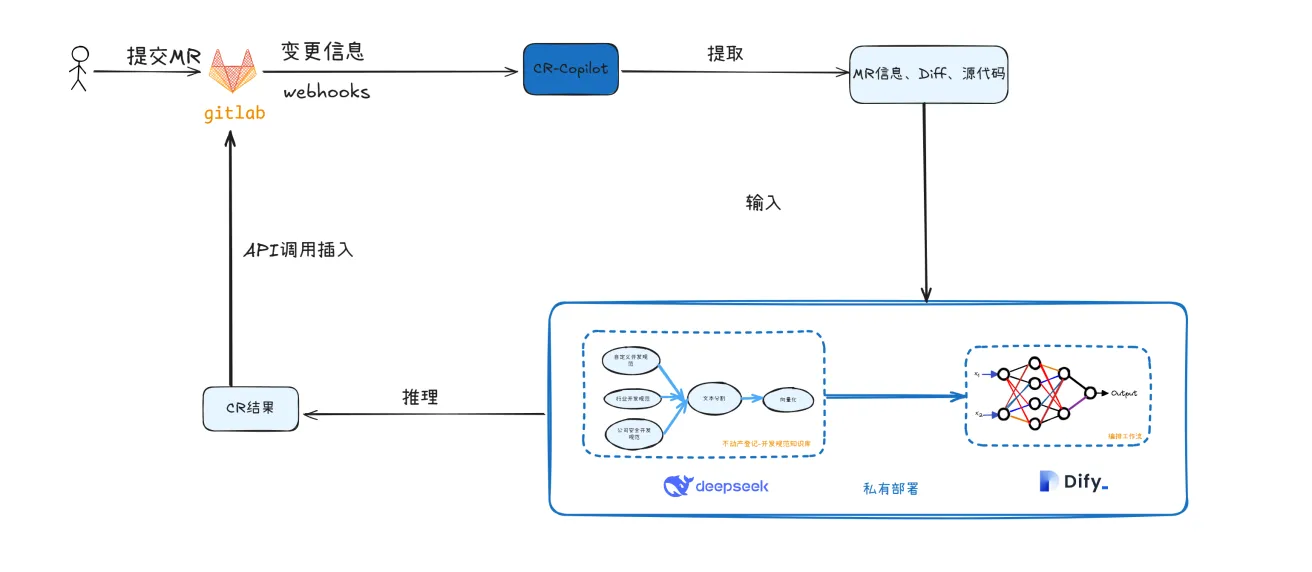
3. 操作步骤
3.1. 申请DeepSeek(与硅基流动二选一)
https://platform.deepseek.com/usage
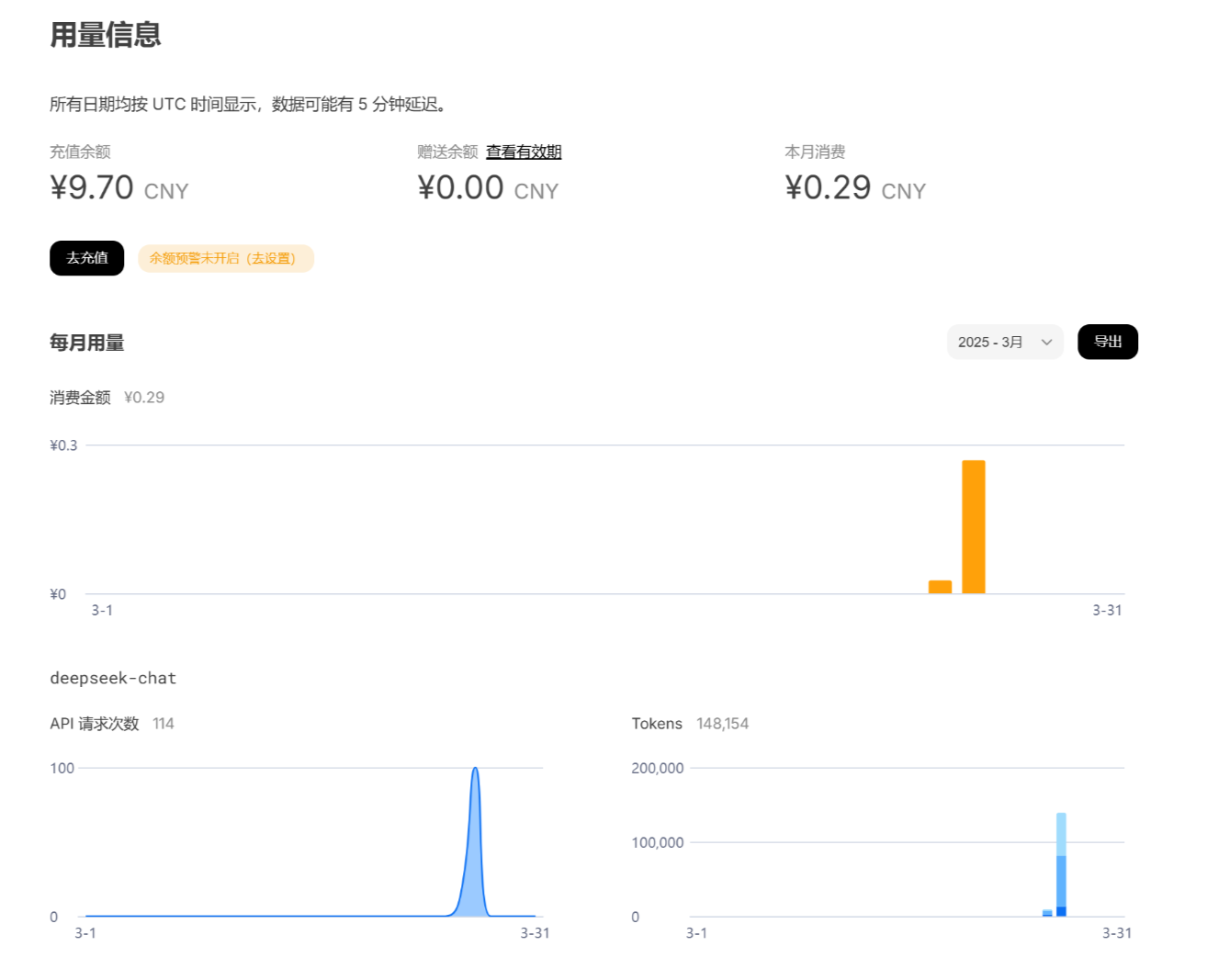
3.1.1. 充值
3.1.2. 申请API key
3.2. 申请硅基流动(与DeepSeek二选一)
3.2.1. 注册赠送14元
3.2.2. 申请ApiKey
3.3. 部署生成式AI应用创新引擎 Dify
-ZLDk.png)
3.3.1. 配置模型
-tuiJ.png)
3.3.2. 搭建私有知识库
上传自定义开发规范、java开发规范、安全开发规范
-jDDq.png)
3.3.3. 搭建工作流
3.3.4. 创建apiKey
3.3.5. 测试效果
3.3.6. 查看调用日志
3.4. 部署内外网穿透(域名)



3.5. 配置GitLab
3.5.1. 配置webhooks
webhooks:
Gitlab在用户触发提交代码、合并请求等一些列操作时,能够将事件的详细信息通过回调的形式,向用户自己配置的接口地址进行调用
http://gtmap-natural.natapp1.cc/code-review,即为CR-Coplilot服务接口地址
3.5.2. 生成访问令牌
生成令牌后,需要妥善保管,因为关闭弹窗后再也复制不了
3.6. 部署CR-Copilot
利用Cursor“零代码”开发,用于对接Gitlab和Dify的Web应用
http://sc.supermap.com/fangyinwei2/cr-copilot
3.6.1. 功能介绍
CR-Copilot是一个基于开源大模型的代码评审助手,它能够自动对GitLab合并请求(MR)中的代码变更进行智能评审。当您在GitLab上创建一个新的合并请求时,CR-Copilot会自动分析代码变更,并在MR的timeline或file changes中提供专业的代码评审意见。
主要特点:
自动识别并分析MR中的代码变更
支持多种AI模型(DeepSeek、Dify知识库等)
灵活配置评审文件类型和规则
实时任务管理和状态跟踪
3.6.2. 系统架构
CR-Copilot主要由以下组件构成:
GitLab集成模块:负责与GitLab API通信,获取MR变更信息并发送评审意见
AI模型调用模块:负责根据配置调用不同的大模型进行代码评审
任务管理模块:负责追踪和管理评审任务的状态
Web服务:提供HTTP接口,接收GitLab webhook回调
3.6.3. 安装与启动
安装依赖:
npm install
启动服务:
npm run start
构建生产版本:
npm run build
3.6.4. 配置说明
{
"api_config_deepseek": {
"host": "https://api.deepseek.com",
"model": "deepseek-chat",
"api_key": "your-api-key"
},
"api_config_dify": {
"host": "http://your-dify-server/v1",
"api_key": "your-dify-api-key"
},
"gitlab_access_token": "your-gitlab-access-token",
"enable_model": "dify",
"code_preview_file_type": ["py", "js", "ts", "jsx", "tsx", "html", "vue", "java", "dart", "yaml", "yml", "properties", "sql", "json", "toml", "ini", "xml"]
}
配置项说明:
api_config_deepseek:DeepSeek模型的配置api_config_dify:Dify知识库的配置gitlab_access_token:GitLab API访问令牌enable_model:启用的AI模型,可选值为"deepseek"或"dify"code_preview_file_type:需要进行代码评审的文件类型
3.7. 部署Ollama(可选)
Ollama用于本地部署大模型,类似于Docker的作用
部署 DeepSeek-R1-8B 模型
3.8. 部署XInference(可选)
https://inference.readthedocs.io/zh-cn/latest/index.html
docker pull xprobe/xinference
docker run -d --name xinference --gpus all -v D:/sof/docker/volumes/xinference/models:/root/models -v D:/sof/docker/volumes/xinference/.xinference:/root/.xinference -v D:/sof/docker/volumes/xinference/.cache/huggingface:/root/.cache/huggingface -e XINFERENCE_HOME=/root/models -p 9997:9997 xprobe/xinference:latest xinference-local -H 0.0.0.0
-d: 让容器在后台运行。
--name xinference: 为容器指定一个名称,这里是xinference。
--gpus all: 允许容器访问主机上的所有GPU,这对于需要进行大量计算的任务(如机器学习模型的推理)非常有用。
-v E:/docker/xinference/models:/root/models, -v E:/docker/xinference/.xinference:/root/.xinference, -v E:/docker/xinference/.cache/huggingface:/root/.cache/huggingface: 这些参数用于将主机的目录挂载到容器内部的特定路径,以便于数据持久化和共享。例如,第一个挂载是将主机的E:/docker/xinference/models目录映射到容器内的/root/models目录。
-e XINFERENCE_HOME=/root/models: 设置环境变量XINFERENCE_HOME,其值为/root/models,这可能是在容器内配置某些应用行为的方式。
-p 9997:9997: 将主机的9997端口映射到容器的9997端口,允许外部通过主机的该端口访问容器的服务。
xprobe/xinference:latest: 指定要使用的镜像和标签,这里使用的是xprobe/xinference镜像的latest版本。
xinference-local -H 0.0.0.0: 在容器启动时执行的命令,看起来像是以本地模式运行某个服务,并监听所有网络接口。
http://127.0.0.1:9997/ui/#/launch_model/llm
评论